
A Practical Guide for GitHub Self-Hosted Runners
Hey everyone, today let’s talk about something that can make a real difference in your CI pipelines: effective caching. If you’ve been following along, you know we’ve explored using Docker registry mirror before. In our last post, we talked about the context and challenge of CI cache in a dynamic and fully scalable environment. Since our setup is like a revolving door with nodes coming and going based on demand, holding onto a Docker cache is like trying to catch smoke with your bare hands. So, when it comes to GitHub Actions self-hosted on EKS, especially with scale sets, caching needs a bit more attention.
Diving into AWS ECR Docker Image Caching
First up, leveraging Docker and Amazon ECR for caching can significantly speed up our builds. AWS’s support for remote cache with BuildKit clients has been a game-changer for us. I read about it here shortly after it was announced and was eager to give it a try. It allows us to efficiently cache Docker images by tagging them with a -builder suffix. This method makes our builds faster because we’re not rebuilding the wheel every time. Here’s how we set it up in a matrix strategy to build our custom runner images, for this example:
- name: Set up Docker Buildx # Dependency requirement for using cache image
uses: docker/setup-buildx-action@master
- name: Construct tag based on the HEAD commit
run: echo "GIT_SHA_SHORT=$(git rev-parse --short=10 HEAD)" >> $GITHUB_ENV
- name: Build and push Docker image
uses: docker/build-push-action@master
with:
context: ./ci_custom_runner
cache-from: type=registry,ref=${{ env.ECR }}:${{ matrix.tag }}-builder
cache-to: type=registry,mode=max,image-manifest=true,oci-mediatypes=true,ref=${{ env.ECR }}:${{ matrix.tag }}-builder
tags: ${{ env.ECR }}:${{ matrix.tag }}-${{ env.GIT_SHA_SHORT }}
push: ${{ inputs.PUSH_IMAGE }}
file: ci_custom_runner/Dockerfile
Notice that we’re using cache-from and cache-to to specify the cache image. This is pretty fast
because we’re using a VPC endpoint for ECR, which means we’re not going over the internet to fetch the
cache image, but using our private network. This is a also plus for NAT cost reduction and security too.
Here’s the build time for a build without caching:
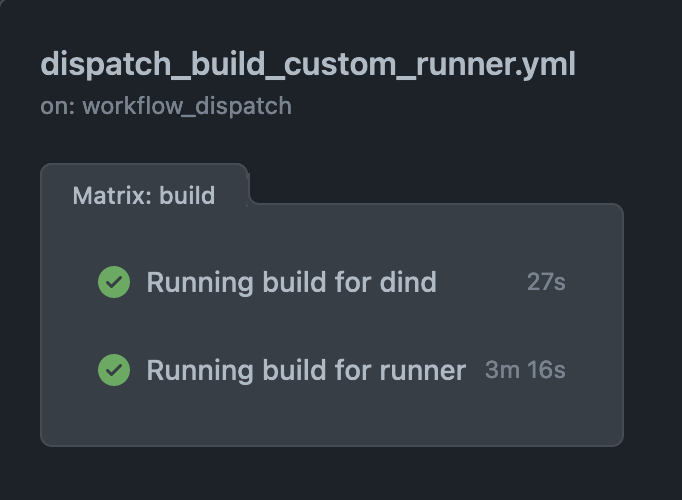
and with caching:
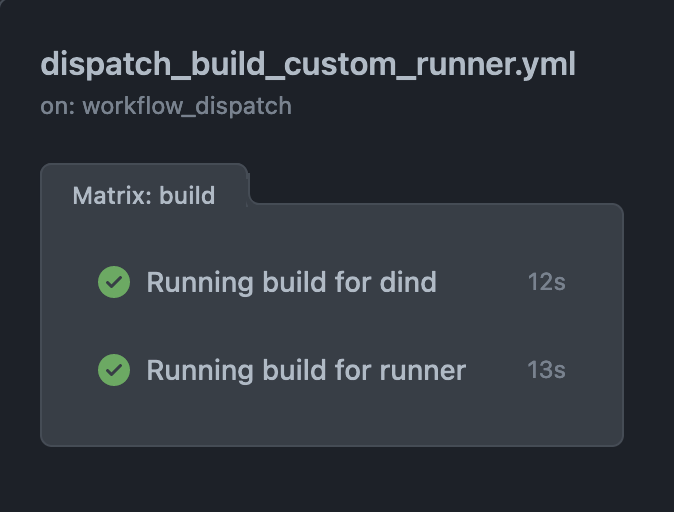
Dockerfile design is important for caching, so try to maximise caching by optimizing the order of
and layers used.
Beyond Default Actions or Going Cache MacGyver with S3
The default caching action provided by GitHub (actions/cache) becomes less efficient in a self-hosted context, particularly when dealing with AWS self-hosted runners and GitHub’s network. The transfer of cache archives across networks introduces delays, potential for transient network failures, and unnecessary NAT costs that can add up. To address these challenges, we devised a custom caching solution that utilizes S3, benefiting from a private network setup that bypasses NAT fees. We are using an S3 gateway for accessing S3 over the private network, which is a great way to avoid NAT costs.
On this scenario, we’re using it for a spring boot application with maven dependencies. We crafted two scripts for this: one to handle cache hits and another for cache misses. This approach ensures we’re only moving what we need, when we need it.
Cache Hit Script:
#!/bin/bash
# Maven repository cache hit script
bucket="s3-cache-bucket-name" # Replace with your S3 bucket name
os_type=$(uname | tr '[:upper:]' '[:lower:]')
hash=$(sha256sum pom.xml | awk '{print $1}')
maven_tarball="${os_type}-${hash}-maven.tar.gz"
maven_tarball_abs_path="${HOME}/${maven_tarball}"
final_maven_remote_path="s3://${bucket}/${maven_tarball}"
cache_hit=false
if aws s3 ls "${final_maven_remote_path}" ; then
echo "Cache hit! Downloading Maven repository tarball..."
aws s3 cp "${final_maven_remote_path}" "${maven_tarball_abs_path}"
mkdir -p ~/.m2
tar -xzf "${maven_tarball_abs_path}" -C ~/.m2
cache_hit=true
fi
echo "CACHE_HIT=${cache_hit}" >> $GITHUB_ENV
The final_maven_remote_path is how we make sure we don’t have partial uploads or downloads, resulting
in corrupted cache.
Cache Miss Script:
#!/bin/bash
# Maven repository cache miss script
bucket="your-s3-bucket-name"
os_type=$(uname | tr '[:upper:]' '[:lower:]')
hash=$(sha256sum pom.xml | awk '{print $1}')
maven_tarball="${os_type}-${hash}-maven.tar.gz"
maven_tarball_abs_path="${HOME}/${maven_tarball}"
final_maven_remote_path="s3://${bucket}/${maven_tarball}"
if ! aws s3 ls "${final_maven_remote_path}" ; then
echo "Cache miss, creating Maven repository tarball..."
tar -czf "${maven_tarball_abs_path}" -C ~/.m2 .
aws s3 cp "${maven_tarball_abs_path}" "${final_maven_remote_path}"
fi
Plugging it into the workflow:
After setting up Java, we check for cache hits with our script. If it’s a miss, we bundle up after the build and upload for next time.
- name: Set up Java
uses: actions/setup-java@v4
with:
distribution: 'corretto'
java-version: '17'
- name: Check cache maven dependencies
run: .bin/cache_hit.sh
- name: Package our app
run: # Your build commands here
- name: Save for later if we missed the cache
if: env.CACHE_HIT == 'false'
run: .bin/cache_miss.sh
This is a maven example, but you can adapt it to other languages and tools. We actually took it a step forward and created a custom action that we use for node and maven projects.
Implementing a Custom GitHub Action for Caching
To further streamline this process and make our caching mechanism reusable across projects, we propose creating a custom GitHub Action. This action would encapsulate the logic of our caching scripts, making it easily shareable and maintainable. Here’s how you can create such an action:
Create a New Repository for Your Action: This repository will host the action code. For clarity, let’s call it custom-cache-action.
Develop Your Action: Inside this repository, create a directory structure that includes:
- A Dockerfile that specifies the environment for running your caching scripts.
- The action.yml file, which defines the inputs, outputs, and main entry point for your action.
- Your caching scripts (cache_hit.sh and cache_miss.sh), modified as necessary to be parameterized based on action inputs.
Define Inputs and Outputs: In action.yml, define the necessary inputs (e.g., pom.xml path, S3 bucket
name) and outputs (e.g., cache hit status).
Your action should now be ready to be used across your organization’s repositories.
Integrate the Custom Action into Your Workflows: Replace the manual cache handling steps in your GitHub Actions workflows with your new custom action, passing the necessary parameters.
In Conclusion
Caching in CI doesn’t have to be a chore. With a bit of creativity and our inner MacGyver we can make our pipelines faster, more efficient, and less costly. It’s all about using the tools AWS gives us, like ECR for Docker image caching, and being clever with how we manage our dependencies with S3. Happy building, everyone!